打造一套真正能落地的 AI 软件解决方案

1.工信部将在 2025 世界人工智能大会上发布《国际人工智能开源合作倡议》
7 月 10 日,上海市政府新闻办举行 2025 世界人工智能大会暨人工智能全球治理高级别会议新闻发布会,介绍大会筹备进展情况。
工业和信息化部科技司副司长杜广达表示,本届大会上,工信部将总结国家人工智能产业发展和赋能应用的趋势和成果,推动国际交流合作。积极倡导全球人工智能的开源合作。以 DeepSeek 为代表的中国大模型,为全球用户提供了高质价比的人工智能产品服务,有力推动人工智能技术在全球的普及应用,向世界贡献了中国智慧。
为进一步推动全球共建开源生态,工信部将推动中国 — 金砖国家人工智能发展与合作中心建设,联合开放原子开源基金会、中国开发者网络、开源中国等机构,在大会上发布《国际人工智能开源合作倡议》,号召全球以开源为纽带,共商技术创新路线,共促技术成果赋能,共建开放包容社区,共享时代发展红利。(澎湃新闻)
2.国家网信办:截至 6 月 30 日,累计有 439 款生成式人工智能服务完成备案
7 月 11 日消息,据“网信中国”微信公众号消息,促进生成式人工智能服务创新发展和规范应用,网信部门会同有关部门按照《生成式人工智能服务管理暂行办法》要求,持续开展生成式人工智能服务备案工作。
4 月至 6 月,新增 93 款生成式人工智能服务在国家网信办完成备案,对于通过 API 接口或其他方式直接调用已备案模型能力的生成式人工智能应用或功能,由地方网信办开展登记,本阶段新增 74 款完成登记。
截至 2025 年 6 月 30 日,累计有 439 款生成式人工智能服务完成备案,233 款生成式人工智能应用或功能完成登记。现将相关信息予以公告。(IT之家)

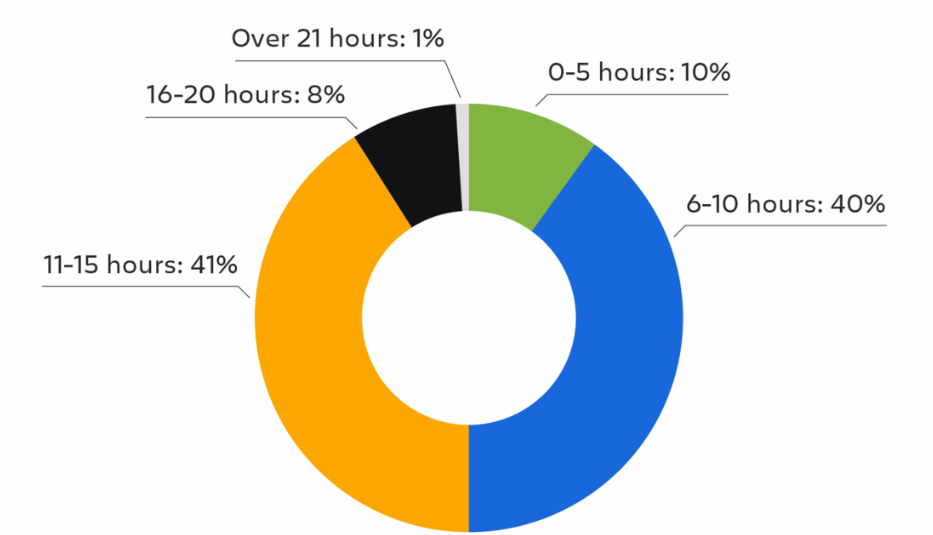
3.报告:68% 的开发者通过使用 AI 每周至少节省 10 小时
Atlassian《2025开发者体验报告》:99%开发者用AI省时间,68%每周省≥10小时,省下的时间多用于提升代码质量、开发新功能、改善工程文化和补文档。
Jellyfish同期报告亦显示90%团队已用AI编码工具,62%称速度提升≥25%。但开发者仅16%时间真正编码,50%每周因查找信息、切换工具等非编码任务浪费逾10小时,AI省出的时间被低效流程抵消。63%认为领导不了解痛点。
报告呼吁:用数据识别障碍、倾听一线声音,把AI嵌入流程、文化与衡量体系,实现从工具升级到组织转型。(OSCHINA,经AI提炼)
4.“全球最强 AI 模型” Grok 4 正式发布
在今天召开的直播活动中,马斯克正式发布了 Grok 4,声称是全球最强 AI 模型,在处理学术问题上的表现已达到博士级别。整场发布会时长 53 分钟,马斯克演示了 Grok 4 模型的多模态功能、更快的推理能力等诸多新特性。
Grok 4 系列包括两个版本:Grok 4 和 Grok 4 Heavy。两者都是纯推理模型,没有非推理模式。Grok 4 是单代理(single agent)版本,而 Grok 4 Heavy 是多代理版本(multi agents),支持四个代理同时工作。上下文窗口最高支持 256k tokens。
xAI 声称,Grok4 在多项基准测试中展现了前沿水准,其中包括 “人类最后一道考题”(Humanity’s Last Exam),这个考试通过数千个关于数学、人文学科和自然科学等主题的众包问题,来衡量 AI 的能力。据 xAI 称,Grok4 在不使用 “工具” 的情况下,在该测试中得分率为 25.4%,超过了 Google Gemini2.5 Pro 的 21.6%,以及 OpenAI 的 o3 (high) 的 21%。
除了 Grok 4 和 Grok4 Heavy,xAI 还推出了其迄今最昂贵的 AI 订阅计划、名为 SuperGrokHeavy 的每月 300 美元的订阅服务。该计划的订阅者将能抢先体验 Grok4 Heavy,并优先使用新功能。此计划与其他主要 AI 提供商如 OpenAI、Google 和 Anthropic 推出的超高端会员服务类似,但 xAI 目前提供了其中最昂贵的订阅选项。
SuperGrok Heavy 的订阅者或许能提前体验到 xAI 计划在未来数月推出的一些新产品。该公司周三表示,一款 AI 编码模型将于 8 月问世,一个多模态智能体将于 9 月推出,而视频生成模型则定于 10 月。(OSCHINA,节选)

5.月之暗面发布旗下首个万亿参数开源模型 Kimi K2,擅长代码与 Agentic 任务
7 月 11 日,月之暗面发布并同步开源新一代万亿级 MoE 大模型 Kimi K2:总参数 1T、激活 32B,采用自研 MuonClip 优化器,在 15.5T token 上完成稳定预训练,零崩溃且 token 利用率提升 40%,在高质量数据瓶颈下开辟新的 Scaling 空间。
官方测试显示,Kimi K2 在 SWE Bench Verified、Tau2、AceBench 等代码、Agent、数学推理基准中全面夺得开源 SOTA,部分指标逼近 GPT-4.1 与 Claude 4。即日起,用户可在官网、App 直接体验;API 同步上线,支持 128K 上下文、兼容 OpenAI/Anthropic 接口,定价 4 元/百万输入、16 元/百万输出。
开源版本同步放出:Kimi-K2-Base 为未微调基础模型,面向科研与自定义;Kimi-K2-Instruct 为指令微调版,适用于通用问答与 Agent 任务。(IT之家,经AI提炼)

图片、内容来自网络,部分内容经AI整合,侵删